🌞 Intro
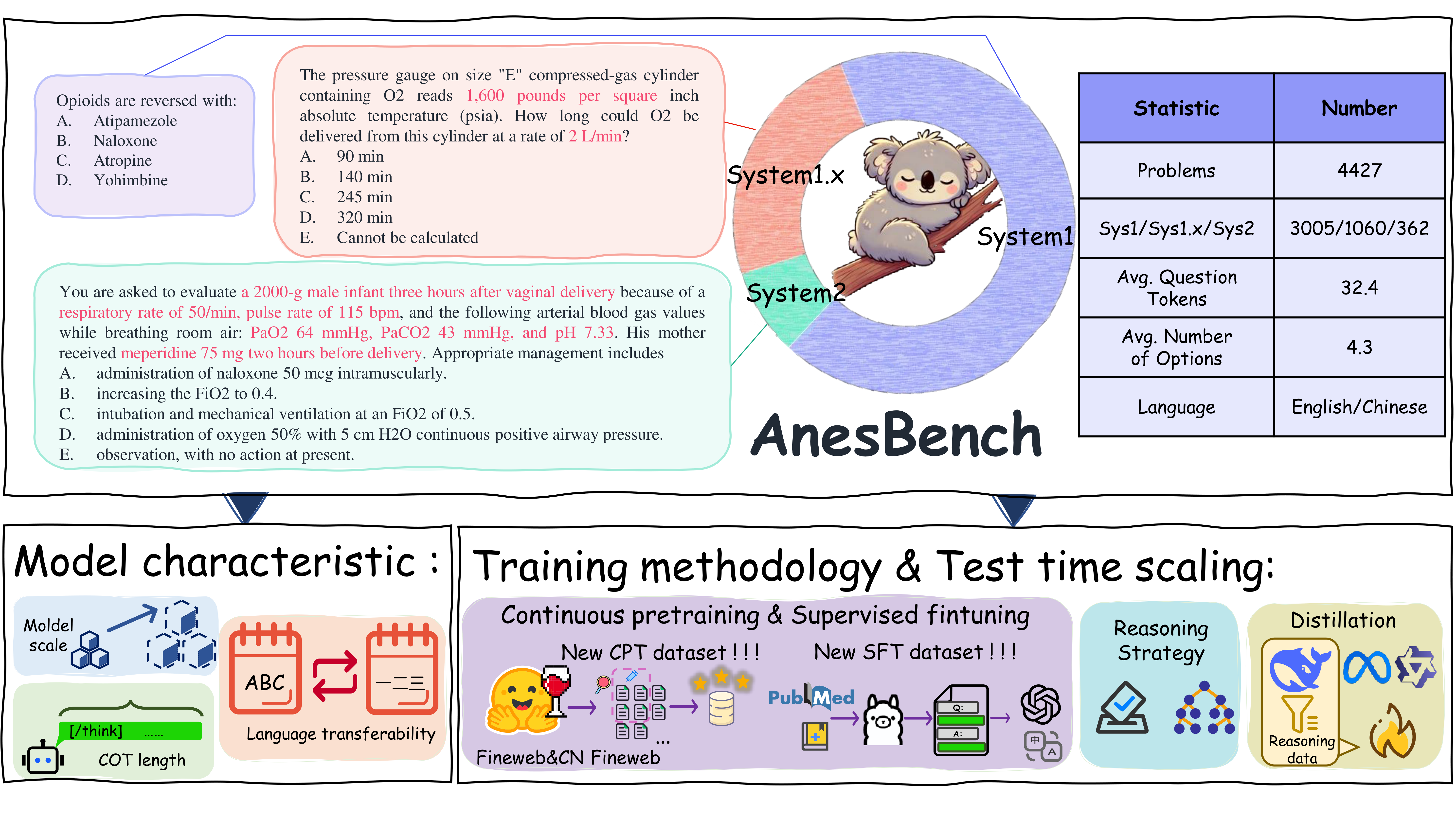
AnesBench is designed to assess anesthesiology-related reasoning capabilities of Large Language Models (LLMs). It contains 4,427 anesthesiology questions in English. Each question is labeled with a three-level categorization of cognitive demands and includes Chinese-English translations, enabling evaluation of LLMs’ knowledge, application, and clinical reasoning abilities across diverse linguistic contexts.
For dataset access, please refer to our Hugging Face repository: AnesBench, AnesQA and AnesCorpus.
For the overview of the dataset, including usage examples and code, please refer to the AnesBench GitHub repository.
🔍 Overview
⭐ Citation
If you find AnesBench helpful, please consider giving this repo a ⭐ and citing:
@article{AnesBench,
title={AnesBench: Multi-Dimensional Evaluation of LLM Reasoning in Anesthesiology},
author={Xiang Feng and Wentao Jiang and Zengmao Wang and Yong Luo and Pingbo Xu and Baosheng Yu and Hua Jin and Bo Du and Jing Zhang},
journal={arXiv preprint arXiv:2504.02404},
year={2025}
}