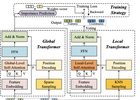
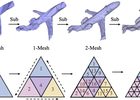
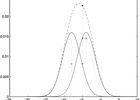
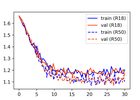
No publications match your search.
2026
arXiv
S Ni, T Wang, J Zhang#, H Chen, H Guo, N Zhang, B Du
arXiv, 2026
arXiv
C Zhang, H Qiu, Q Zhang, Y Xu, X Gao, J Zhang#
arXiv, 2026
arXiv
X Feng, J Zhou, Z Huang, K Wang, S Ye, J Hu, Z Chen, Y Luo, J Zhang#
arXiv, 2026
ICML
H Chen, J Zhang#, H Wang, S Wang, P Huang, J Li, H Guo, D Wang
ICML, 2026
ICML
F Wang, M Chen, Y Li, Y Yang, Y Zhou, D Wang, Y Zhang, H Wang, H Zhao, H Sun, L Lan, J Song, Y Wang, J Zhang, W Zhang, B Du
ICML, 2026
ICML
B Wang, D Wang, H Guo, Y Fu, J Zhang#
ICML, 2026
arXiv
J Zhang, D Chen, W Jiang, Z Lou, J Liu, X Cui, Q Zhao, B Du, CF Dietrich
arXiv, 2026
ACL
J Zhou, C Zhang, X Feng, Q Zhang, H Qiu, L He, D Ye, X Gao, J Zhang#
ACL, 2026
IJCV
K Huang, S Zhang, J Zhang#, D Tao
IJCV, 2026
arXiv
H Wang, J Zhang#, H Guo, D Wang, J Ma, B Du, L Zhang
arXiv, 2026
arXiv
Y Liu, J Zhang#, D Wang, X Tian, H Guo, B Du
arXiv, 2026
CVPR
X Zhang, Z Chen, J Zhang, D Tao
CVPR, 2026
CVPR
Z Song, J Zhang#, D Wang, Z Zhou, W Liu, H Guo, E Wang, B Du
CVPR, 2026
CVPR
S Ni, D Wang, H Chen, H Guo, N Zhang, J Zhang#
CVPR, 2026
CVPR
D Liu, D Wang, H Wang, H Chen, W Jiang, Y Cheng, H Guo, W Cui, J Zhang
CVPR, 2026
CVPR
C Zhang, H Qiu, Q Zhang, Y Xu, Z Zeng, S Yang, P Shi, L Ma, J Zhang#
CVPR, 2026
CVPRHighlight
H Wang, J Zhang#, H Chen, H Guo, D Wang, J Ma, B Du
CVPR, 2026
CVPR
C Zhang, H Qiu, Q Zhang, Z Zeng, L Ma, J Zhang#
CVPR Findings, 2026
arXiv
F Wang, M Chen, Y Li, Y Yang, Y Zhang, L Lan, X Yang, H Sun, Y Wang, D Wang, J Song, J Zhang, B Du
arXiv, 2026
arXiv
Z Luo, D Wang, H Guo, J Zhang, B Du
arXiv, 2026
arXiv
Z Lou, J Fan, S Ma, Y Yang, J Zhang#
arXiv, 2026
ICLR
X Feng, W Jiang, Z Wang, Y Luo, P Xu, B Yu, H Jin, J Zhang#
ICLR, 2026
2025
TPAMI
Z Gong, Z Wei, D Wang, X Hu, X Ma, H Chen, Y Jia, Y Deng, Z Ji, X Zhu, X Yang, N Yokoya, J Zhang, B Du, J Yan, L Zhang
IEEE TPAMI, 2025
arXiv
D Wang, S Liu, W Jiang, F Wang, Y Liu, X Qin, Z Luo, C Zhou, H Guo, J Zhang, B Du, D Tao, L Zhang
arXiv, 2025
AAAIOral
L Lv, D Wang, J Zhang#, L Zhang
AAAI, 2025
NeurIPS
F Wang, Y Wang, M Chen, H Zhao, Y Sun, S Wang, H Wang, D Wang, L Lan, W Yang, J Zhang#
NeurIPS, 2025
NeurIPSSpotlight
F Wang, M Chen, Y Li, D Wang, H Wang, Z Guo, Z Wang, B Shan, L Lan, Y Wang, H Wang, W Yang, B Du, J Zhang
NeurIPS, 2025
NeurIPS
H Wang, J Zhang#, H Guo, D Wang, J Ma, B Du
NeurIPS, 2025
arXiv
W Jiang, X Feng, Z Wang, Y Luo, P Xu, Z Chen, B Du, J Zhang#
arXiv, 2025
ICCV
Z Zhang, L Dai, Q Lin, Y Diao, G Jin, Y Guo, J Zhang, X Hao
ICCV, 2025
ICCV
W Xuan, J Zhang#, J Liu, B Du, D Tao
ICCV, 2025
ICCV
F Wang, H Wang, D Wang, Z Guo, Z Zhong, L Lan, W Yang, J Zhang#
ICCV, 2025
TPAMI
L Duan, S Zhao, X Weng, J Zhang, GS Xia
IEEE TPAMI, 2025
arXiv
F Wang, M Chen, X He, YF Zhang, Y Li, F Liu, Z Guo, Z Hu, J Wang, J Xu, Z Li, J Gong, D Wang, F Ling, B Fei, W Li, L Lan, W Yang, J Zhang, W Zhang, L Bai
arXiv, 2025
arXiv
M Ye, H He, Q Zhong, J Zhang#, J Liu, B Du
arXiv, 2025
arXiv
J Fan, X Zeng, J Zhang, M Gong, Y Yang, D Tao
arXiv, 2025
ACL
Y Ding, W Jiang, S Liu, Y Jing, J Guo, Y Wang, J Zhang, Z Wang, Z Liu
ACL, 2025
ACL
L Zhang, X Hao, Q Xu, Q Zhang, X Zhang, P Wang, J Zhang, Z Wang
ACL, 2025
arXiv
X Qin, D Wang, J Zhang#, F Wang, X Su, B Du, L Zhang
arXiv, 2025
ICML
X Hao, L Liu, Y Diao, R Yin, P Wang, J Zhang, L Kong, S Zhao
ICML, 2025
IJCAI
F Hao, F He, Y Wang, F Wu, J Zhang, J Cheng, D Tao
IJCAI, 2025
IJCAI
H Gu, J Fan, L Zheng, J Zhang, Y Yang
IJCAI, 2025
IJCAI
Y Yang, Y Deng, M Pan, ZJ Zha, J Zhang#
IJCAI, 2025
IJCAI
T Zhe, M Han, X Hao, Y Luo, Z He, X Cai, J Zhang
IJCAI, 2025
TPAMI
Z Zhang, G Wu, J Zhang, X Zhu, D Tao, T Chai
IEEE TPAMI, 2025
TPAMI
D Wang, M Hu, Y Jin, Y Miao, J Yang, Y Xu, X Qin, J Ma, L Sun, C Li, C Fu, H Chen, C Han, N Yokoya, J Zhang, M Xu, L Liu, L Zhang, C Wu, B Du, D Tao, L Zhang
IEEE TPAMI, 2025
arXiv
C Zhang, C Feng, F Yan, Q Zhang, M Zhang, Y Zhong, J Zhang#, L Ma
arXiv, 2025
CVPRHighlight
F Wang, H Wang, M Chen, D Wang, Y Wang, Z Guo, Q Ma, L Lan, W Yang, J Zhang, Z Liu, M Sun
CVPR, 2025
CVPR
M Zhang, X Li, F Gao, J Guo, X Gao, J Zhang
CVPR, 2025
2024
IJCV
S Qu, G Chen, J Zhang, Z Li, W He, D Tao
IJCV, 2024
AAAI
Y Yang, H Gu, Y Deng, Z Dong, Z He, J Zhang#
AAAI, 2024
AAAI
M Zhang, W Shang, F Gao, Q Zhang, FQ Lu, J Zhang
AAAI, 2024
AAAI
M Zhang, Y Ouyang, F Gao, J Guo, Q Zhang, J Zhang
AAAI, 2024
TPAMI
M Ye, J Zhang, J Liu, C Liu, B Yin, C Liu, B Du, D Tao
IEEE TPAMI, 2024
NeurIPS
X Hao, M Wei, Y Yang, H Zhao, H Zhang, Y Zhou, Q Wang, W Li, L Kong, J Zhang
NeurIPS, 2024
NeurIPS
H He, M Ye, J Zhang#, J Liu, D Tao
NeurIPS, 2024
IJCV
X Zhang, Z Chen, J Zhang#, T Liu, D Tao
IJCV, 2024
ACMMM
W Lu, Y Xu, J Zhang#, C Wang, D Tao
ACM MM, 2024
ACMMM
T Zhe, J Zhang, Y Li, Y Luo, H Hu, D Tao
ACM MM, 2024
ACMMM
X Lv, Z He, Y Yang, J Nie, J Zhang
ACM MM, 2024
ACMMM
M Zhang, C Zhang, Q Zhang, Y Li, X Gao, J Zhang
ACM MM, 2024
ECCV
M Zhang, Y Wang, J Guo, Y Li, X Gao, J Zhang
ECCV, 2024
ECCV
X Hao, R Li, H Zhang, D Li, R Yin, S Jung, SI Park, BI Yoo, H Zhao, J Zhang
ECCV, 2024
IJCV
Q Zheng, D Liu, C Wang, J Zhang#, D Wang, D Tao
IJCV, 2024
arXiv
S Ma, J Zhang, Q Cao, D Tao
arXiv, 2024
TPAMI
J Gui, T Chen, J Zhang, Q Cao, Z Sun, H Luo, D Tao
IEEE TPAMI, 2024
TIP
Y Xie, H Wu, J Zhu, H Zeng, J Zhang
IEEE TIP, 2024
IJCAI
W Jiang, J Zhang, D Wang, Q Zhang, Z Wang, B Du
IJCAI, 2024
CVPR
H Zhao, J Zhang*, Z Chen, S Zhao, D Tao
CVPR, 2024
CVPR
X Cong, J Gui, J Zhang, J Hou, H Shen
CVPR, 2024
Workshop
J Zhang
SUMAC @ ACM Multimedia, 2024
2023
TPAMI
H He, J Liu, Z Pan, J Cai, J Zhang, D Tao, B Zhuang
IEEE TPAMI, 2023
arXiv
Y Yang, Y Deng, Y Xu, J Zhang#
arXiv, 2023
arXiv
W Yue, J Zhang#, K Hu, Q Wu, Z Ge, Y Xia, J Luo, Z Wang
arXiv, 2023
TPAMI
Q Zhang, J Zhang*#, Y Xu, D Tao
IEEE TPAMI, 2023
AAAI
X Yang, D Liu, H Zhang, Y Luo, C Wang, J Zhang
AAAI, 2023
AAAI
M Zhang, H Yang, J Guo, Y Li, X Gao, J Zhang#
AAAI, 2023
AAAI
W Yue, J Zhang, K Hu, Y Xia, J Luo, Z Wang
AAAI, 2023
AAAI
H Zhao, Q Zhang, S Zhao, Z Chen, J Zhang, D Tao
AAAI, 2023
IJCV
H Luo, W Zhai, J Zhang, Y Cao, D Tao
IJCV, 2023
TPAMI
Y Xu, J Zhang*#, Q Zhang, D Tao
IEEE TPAMI, 2023
TPAMI
W Zhai, Y Cao, J Zhang, H Xie, D Tao, ZJ Zha
IEEE TPAMI, 2023
NeurIPS
D Wang, J Zhang, B Du, M Xu, L Liu, D Tao, L Zhang
NeurIPS, 2023
TPAMI
H He, J Zhang*, B Zhuang, J Cai, D Tao
IEEE TPAMI, 2023
ACMMM
S Ma, Q Cao, H Yi, J Zhang, D Tao
ACM MM, 2023
ACMMM
J Fan, J Zhang, Z Hou, D Tao
ACM MM, 2023
TPAMI
H Xu, J Zhang, J Cai, H Rezatofighi, F Yu, D Tao, A Geiger
IEEE TPAMI, 2023
ICCV
H Wang, H Chi, W Yang, Z Lin, M Geng, L Lan, J Zhang, D Tao
ICCV, 2023
ICCV
M Zhang, C Zhang, Q Zhang, J Guo, X Gao, J Zhang
ICCV, 2023
ICCV
H He, J Cai, J Zhang, D Tao, B Zhuang
ICCV, 2023
IJCV
S Zhao, M Gong, H Zhao, J Zhang, D Tao
IJCV, 2023
IJCV
Z Chen, J Zhang, Y Xu, D Tao
IJCV, 2023
TIP
L Lan, X Teng, J Zhang, X Zhang, D Tao
IEEE TIP, 2023
arXiv
H He, J Zhang, M Xu, J Liu, B Du, D Tao
arXiv, 2023
IJCV
B Ma, J Zhang, Y Xia, D Tao
IJCV, 2023
IJCAI
J Nie, Z He, Y Yang, Z Bao, M Gao, J Zhang
IJCAI, 2023
TIP
D Wang, J Zhang, B Du, L Zhang, D Tao
IEEE TIP, 2023
arXiv
J Li, J Zhang, D Tao
arXiv, 2023
IJCV
S Ma, J Li, J Zhang#, H Zhang, D Tao
IJCV, 2023
arXiv
K Liao, L Nie, S Huang, C Lin, J Zhang, Y Zhao, M Gabbouj, D Tao
arXiv, 2023
CVPR
H Luo, W Zhai, J Zhang, Y Cao, D Tao
CVPR, 2023
CVPR
M Ye, J Zhang*, S Zhao, J Liu, T Liu, B Du, D Tao
CVPR, 2023
CVPR
X Zhang, W Wang, Z Chen, Y Xu, J Zhang, D Tao
CVPR, 2023
CVPR
J Li, J Zhang, D Tao
CVPR, 2023
CVPR
H He, J Cai, Z Pan, J Liu, J Zhang, D Tao, B Zhuang
CVPR, 2023
2022
TPAMI
T Feng, Y Zhai, J Yang, J Liang, DP Fan, J Zhang, L Shao, D Tao
IEEE TPAMI, 2022
AAAI
J Nie, Z He, Y Yang, M Gao, J Zhang
AAAI, 2022
AAAI
M Lan, J Zhang, L Zhang, D Tao
AAAI, 2022
AAAI
M Ye, J Zhang, S Zhao, J Liu, B Du, D Tao
AAAI, 2022
NeurIPSSpotlight
Y Yang, J Yang, Y Xu, J Zhang#, L Lan, D Tao
NeurIPS, 2022
NeurIPS
W Zhai, Y Cao, J Zhang, ZJ Zha
NeurIPS, 2022
NeurIPSSpotlight
Q Wang, F Liu, Y Zhang, J Zhang, C Gong, T Liu, B Han
NeurIPS, 2022
NeurIPS
Y Xu, J Zhang*, Q Zhang, D Tao
NeurIPS, 2022
IJCV
S Zhang, J Zhang#, D Tao
IJCV, 2022
ECCV
Y Liang, S Zhao, B Yu, J Zhang, F He
ECCV, 2022
ECCV
H Zhao, J Zhang#, S Zhang, D Tao
ECCV, 2022
ECCV
Z Li, C Wang, H Zheng, J Zhang, B Li
ECCV, 2022
ECCV
D Shi, Y Zhong, Q Cao, J Zhang, L Ma, J Li, D Tao
ECCV, 2022
ECCV
S Zhang, J Zhang, D Tao
ECCV, 2022
ECCV
Q Zhang, Y Xu, J Zhang, D Tao
ECCV, 2022
ECCV
S Qu, G Chen, J Zhang, Z Li, W He, D Tao
ECCV, 2022
ECCV
W Wang, J Zhang*, Y Cao, Y Shen, D Tao
ECCV, 2022
ECCV
H Yuan, X Li, Y Yang, G Cheng, J Zhang, Y Tong, L Zhang, D Tao
ECCV, 2022
ECCV
Y Xu, Q Zhang, J Zhang, D Tao
ECCV, 2022
ACMMM
N Wang, J Zhang, L Zhang, D Tao
ACM MM, 2022
ACMMM
M Zhang, K Yue, J Zhang, Y Li, X Gao
ACM MM, 2022
ACMMM
M Zhang, H Bai, J Zhang#, R Zhang, C Wang, J Guo, X Gao
ACM MM, 2022
IJCV
W Zhai, H Luo, J Zhang, Y Cao, D Tao
IJCV, 2022
arXiv
W Li, Q Zhang, J Zhang, Z Huang, X Tian, D Tao
arXiv, 2022
TIP
Y Xu, J Zhang, SJ Maybank, D Tao
IEEE TIP, 2022
IJCAI
M Zhang, C He, J Zhang, Y Yang, X Peng, J Guo
IJCAI, 2022
arXiv
Z Li, B Xia, J Zhang, C Wang, B Li
arXiv, 2022
IJCV
B Du, J Ye, J Zhang, J Liu, D Tao
IJCV, 2022
CVPR
X Chen, Q Cao, Y Zhong, J Zhang, S Gao, D Tao
CVPR, 2022
CVPR
M Zhang, R Zhang, Y Yang, H Bai, J Zhang#, J Guo
CVPR, 2022
CVPR
X Lin, C Ding, J Zhang, Y Zhan, D Tao
CVPR, 2022
CVPR
H Luo, W Zhai, J Zhang#, Y Cao, D Tao
CVPR, 2022
CVPR
Y Feng, B Ma, J Zhang, S Zhao, Y Xia, D Tao
CVPR, 2022
CVPROral
Z Chen, J Zhang, D Tao
CVPR, 2022
CVPROral
H Xu, J Zhang, J Cai, H Rezatofighi, D Tao
CVPR, 2022
IJCV
Q Zhang, Y Xu, J Zhang, D Tao
IJCV, 2022
ICLR
W Wang, Y Cao, J Zhang, D Tao
ICLR, 2022
2021
TIP
W Wang, J Zhang*, W Zhai, Y Cao, D Tao
IEEE TIP, 2021
AAAI
C Chen, Z Chen, J Zhang, D Tao
AAAI, 2021
AAAI
Y He, C Chen, J Zhang, J Liu, F He, C Wang, B Du
AAAI, 2021
AAAI
M Lan, J Zhang, F He, L Zhang
AAAI, 2021
IJCV
J Fan, J Zhang, SJ Maybank, D Tao
IJCV, 2021
IJCV
Y Yang, Q Cao, J Zhang#, D Tao
IJCV, 2021
IJCV
J Li, J Zhang*, SJ Maybank, D Tao
IJCV, 2021
NeurIPS
H Yu, Y Xu, J Zhang#, W Zhao, Z Guan, D Tao
NeurIPS, 2021
NeurIPS
Y Xu, Q Zhang, J Zhang, D Tao
NeurIPS, 2021
IJCV
J Zhang, Z Chen, D Tao
IJCV, 2021
IJCAI
J Li, J Zhang, D Tao
IJCAI, 2021
IJCAI
H Luo, W Zhai, J Zhang#, Y Cao, D Tao
IJCAI, 2021
IJCAI
J Gui, X Cong, Y Cao, W Ren, J Zhang, J Zhang, D Tao
IJCAI, 2021
ICCV
Y Xu, J Zhang, D Tao
ICCV, 2021
ACMMM
W Wang, Y Cao, J Zhang#, F He, ZJ Zha, Y Wen, D Tao
ACM MM, 2021
ACMMM
L Gao, J Zhang, L Zhang, D Tao
ACM MM, 2021
ACMMM
J Li, S Ma, J Zhang, D Tao
ACM MM, 2021
2020
AAAI
H He, J Zhang, B Thuraisingham, D Tao
AAAI, 2020
TIP
J Fan, J Zhang, D Tao
IEEE TIP, 2020
NeurIPS
B Ma, J Zhang*, Y Xia, D Tao
NeurIPS, 2020
ACMMM
J Zhang, Y Cao, ZJ Zha, D Tao
ACM MM, 2020
IJCV
Z Chen, J Zhang#, D Tao
IJCV, 2020
CVPROral
Y Wang, Y Cao, ZJ Zha, J Zhang, Z Xiong
CVPR, 2020
2019
NeurIPS
T Qiao, J Zhang*, D Xu, D Tao
NeurIPS, 2019
NeurIPS
Q Zhang, J Zhang*, W Liu, D Tao
NeurIPS, 2019
AAAIOral
H He, J Zhang*, Q Zhang, D Tao
AAAI, 2019
ACMMM
Y Wang, Y Cao, ZJ Zha, J Zhang, Z Xiong, W Zhang, F Wu
ACM MM, 2019
ICCV
W Zhai, Y Cao, J Zhang, ZJ Zha
ICCV, 2019
AAAI
H Wen, J Zhang*, Q Lin, K Yang, P Huang
AAAI, 2019
CVPR
T Qiao, J Zhang#, D Xu, D Tao
CVPR, 2019
TIP
J Zhang, D Tao
IEEE TIP, 2019
2018
ACMMM
J Zhang, Y Cao, Y Wang, C Wen, CW Chen
ACM MM, 2018
2017
CVPR
J Zhang, Y Cao, S Fang, Y Kang, CW Chen
CVPR, 2017